Einen Teil unserer Analysen aus der Perspektive des distant reading machen Referenzanalysen aus, ein anderer besteht in der automatisierten, also computergestützten Analyse von Texten. So ist es uns z.B. möglich, Volltexte aus unserem Datensatz miteinander zu vergleichen…
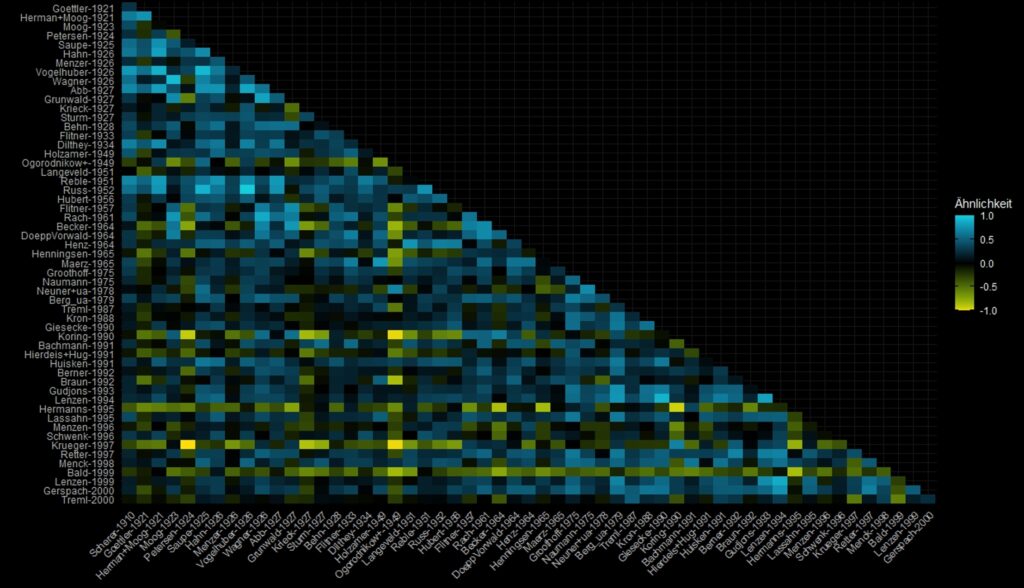
um semantischen (Un-)Ähnlichkeiten auf die Spur zu kommen, oder Begriffe und Begriffsgruppen innerhalb der Werke über typische Abweichungen oder via Topic Modeling als irgendwie besondere semantische Phänomene zu identifizieren.

Diese abstrakten Analysen liefern – aus der Perspektive der erziehungwissenschaftlich interessierten Wissens- oder Bildungsgeschichtsforschung – keine letztgültigen Antworten, aber sie können interessante Ausgangspunkte markieren, die auf anderen Wegen nicht sichtbar hätten gemacht werden können.
Beispiele dafür finden sich in unserem Abschlussbericht (i.B.).